

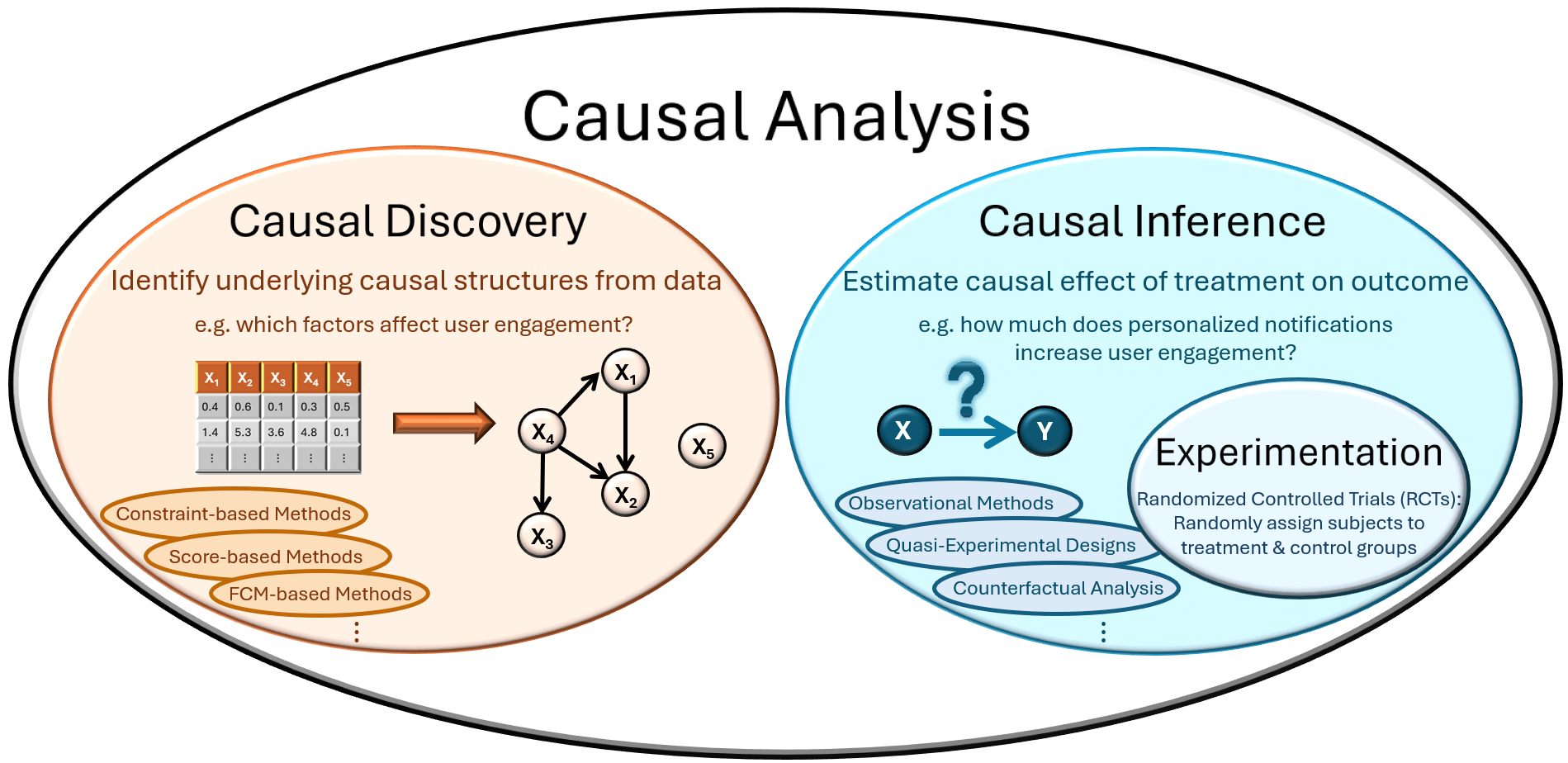
In the world of inquiry and uncertainty, data behaves like light refracting through a prism—what we see depends on the angle from which we observe. The work of understanding causality—what truly causes what—is the art of adjusting that prism to reveal the unseen spectrum behind correlations. When assumptions are incomplete or when key variables are hidden from view, non-parametric methods step in not as fortune-tellers, but as cartographers—mapping the bounds within which causal truth may lie.
The Imperfect Lens: Why Causality Often Hides in Shadows
In many studies, researchers dream of perfect experiments where everything is observable and controllable. But the real world rarely obliges. A marketing team may not know which users were exposed to a campaign organically, a doctor might miss lifestyle factors influencing patient recovery, and a policymaker may not capture every socio-economic ripple of a new regulation.
Traditional causal models—those dependent on parametric assumptions—tend to fill in these gaps with mathematical guesses. Non-parametric bounding, however, resists the urge to guess. It says, “Let’s not pretend we know the missing puzzle pieces; instead, let’s determine the range of answers consistent with what we do know.” This humility is its strength.
It’s this perspective that often excites learners in a data scientist course, where the goal is not to worship models but to understand their limits. Bounding methods don’t produce single-point estimates but rather intervals—a spectrum of possible causal effects that reflect reality’s uncertainty.
The First Case: Public Health and the Range of Reality
Imagine a public health study examining whether providing free gym memberships reduces obesity rates. The complication? Some participants receive gym memberships but never use them, while others—motivated by the idea—start exercising on their own. The data becomes messy, confounded, and full of hidden influences.
Instead of forcing assumptions about exercise compliance or motivation, researchers can use non-parametric bounds (like the Manski bounds) to calculate the possible range of causal effects. The result: policymakers learn that gym access might reduce obesity by as little as 2% or as much as 12%.
That range may sound vague, but it’s an honest portrait of uncertainty—a compass pointing to what’s possible rather than a false claim of precision. For anyone pursuing a data science course in Pune, such examples highlight why responsible causal inference values transparency over neatness.
The Second Case: Credit Scoring and Ethical Fairness
In the financial sector, fairness in credit scoring has become a pressing issue. Suppose a bank wants to know whether its AI-based scoring system unfairly penalizes certain applicants. Yet the data on applicants’ true creditworthiness—free from bias—is unavailable.
Here, non-parametric bounding methods help estimate the possible extent of discrimination, without making rigid assumptions about the missing data. By using these techniques, analysts can report: “Even under the most optimistic assumptions, bias may account for between 5% and 15% of rejections.”
This bounded insight forces institutions to confront systemic uncertainty. It’s not about guessing whether the model is fair—it’s about understanding how fair it could possibly be. For students exploring a data scientist course, this mindset is transformative: it teaches that acknowledging uncertainty is not weakness, but integrity.
The Third Case: Education Policy and the Invisible Variables
Consider a government trying to evaluate the effect of laptop distribution programs in rural schools. They want to know: do laptops improve test scores? The problem: not all schools have stable electricity, qualified teachers, or parental support—variables that aren’t fully captured in the dataset.
Applying non-parametric bounds allows researchers to avoid overclaiming success or failure. The analysis might show that laptops improve scores by between 0% and 20%, depending on unobserved factors. That bounded result guides realistic expectations—it helps policymakers recognize where further support (like teacher training or infrastructure) is needed to make technology effective.
When students in a data science course in Pune encounter such examples, they learn that causal inference isn’t just about math—it’s about ethics, humility, and the courage to communicate uncertainty clearly.
Beyond Numbers: The Philosophy Behind Bounding
Bounding causal effects isn’t just a statistical tool—it’s a worldview. It accepts that in the grand experiment of life, we cannot control or observe everything. Yet, by embracing uncertainty, we can make better, fairer, and more transparent decisions.
Non-parametric methods ask: What can we conclude without overpromising? They’re a way of saying, “Here’s the truth we can defend, even when the data hides secrets.” This philosophy has begun to reshape research across domains—from epidemiology to AI fairness—reminding analysts that the goal isn’t to be omniscient but to be honest.
Students mastering these principles through a data scientist course quickly realize that responsible modeling often means acknowledging the limits of knowledge. They learn to balance rigor with realism—an essential trait in an era obsessed with certainty.
Conclusion: Mapping the Unknown with Integrity
In the quest to understand cause and effect, non-parametric bounding methods act as navigational maps through foggy terrain. They don’t clear the mist, but they show the safe passages—the range where truth may dwell.
In practice, these methods have shaped public policy, fairness in AI, and evidence-based governance. They remind us that uncertainty is not an obstacle but a guidepost, helping us make grounded decisions amid imperfect information.
For learners exploring a data science course in Pune or a data scientist course, this topic serves as a profound lesson: the future of data science is not about perfect predictions, but about principled reasoning under uncertainty. In that humility lies the true art of understanding causality—honest, bounded, and beautifully imperfect.
Business Name: ExcelR – Data Science, Data Analytics Course Training in Pune
Address: 101 A ,1st Floor, Siddh Icon, Baner Rd, opposite Lane To Royal Enfield Showroom, beside Asian Box Restaurant, Baner, Pune, Maharashtra 411045
Phone Number: 098809 13504
Email Id: enquiry@excelr.com